KMeans算法有两个假设:
-
“簇中心点”是属于该簇的所有数据点坐标的算术平均值。
-
一个簇的每个点到该簇中心点的距离,比到其他簇中心点的距离短。
sklearn实例
数据
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples = 300, centers = 4, cluster_std=0.5, random_state=0)用sklearn生成一个示例数据。我们画个图看看:
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], s=50)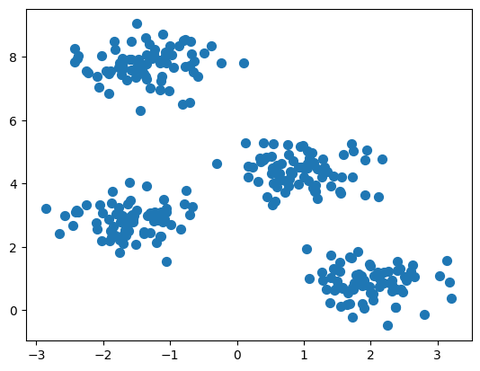
很清楚,就是4个类。然后我们用kmeans算法来聚类。
KMeans聚类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_pred = kmeans.predict(X)sklearn的套路:1. 初始化模型(包括指定一些超参数),2. 拟合数据(或者叫训练),3. 预测。打完收工,我们画个图看看:
plt.scatter(X[:, 0], X[:, 1], s=50, c=y_pred, cmap='viridis')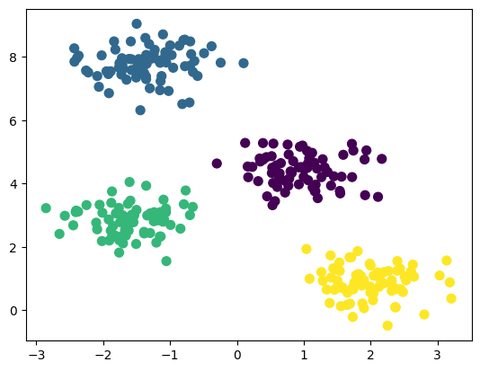
我们也可以把中心点画在上面:
plt.scatter(X[:, 0], X[:, 1], s=50, c=y_pred, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.8)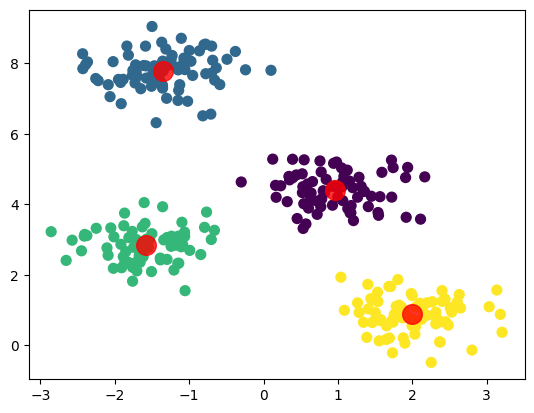
自己写个KMeans的乐趣
自己写的一个好处是你可以记录一下迭代过程中的中心点位置,然后拿来画图,对于KMeans的过程会有直观的感受,你也会发现收敛得很快。这就是我在2011年的时候用R写的代码出的图:
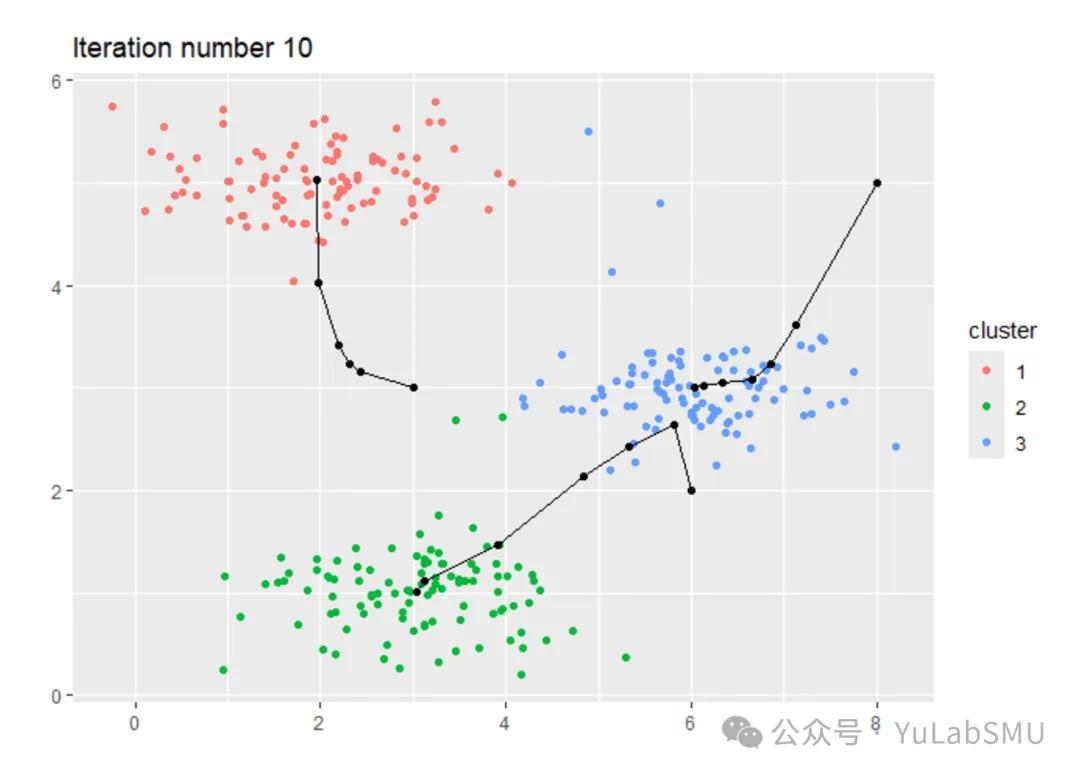
此处还有一段用Python写的KMeans可供参考。
KMeans还能干点啥?
它能做图片压缩,对颜色进行聚类,然后用中心点去替换相似的颜色,比如说一张图,你给压缩成16色的,图片就可以小很多。这也是当年写了KMeans之后,干过的一件事情。然后还可以有一个类似的事情可以干,我把图片颜色的中心点拿出来,这不等到把配色方案拿到手了么?然后你就可以将其应用于自己的图中。也就是说你上班摸鱼在看图,就有借口说自己在找配色方案了。这就是当年写下这篇《食色性也》所介绍的。
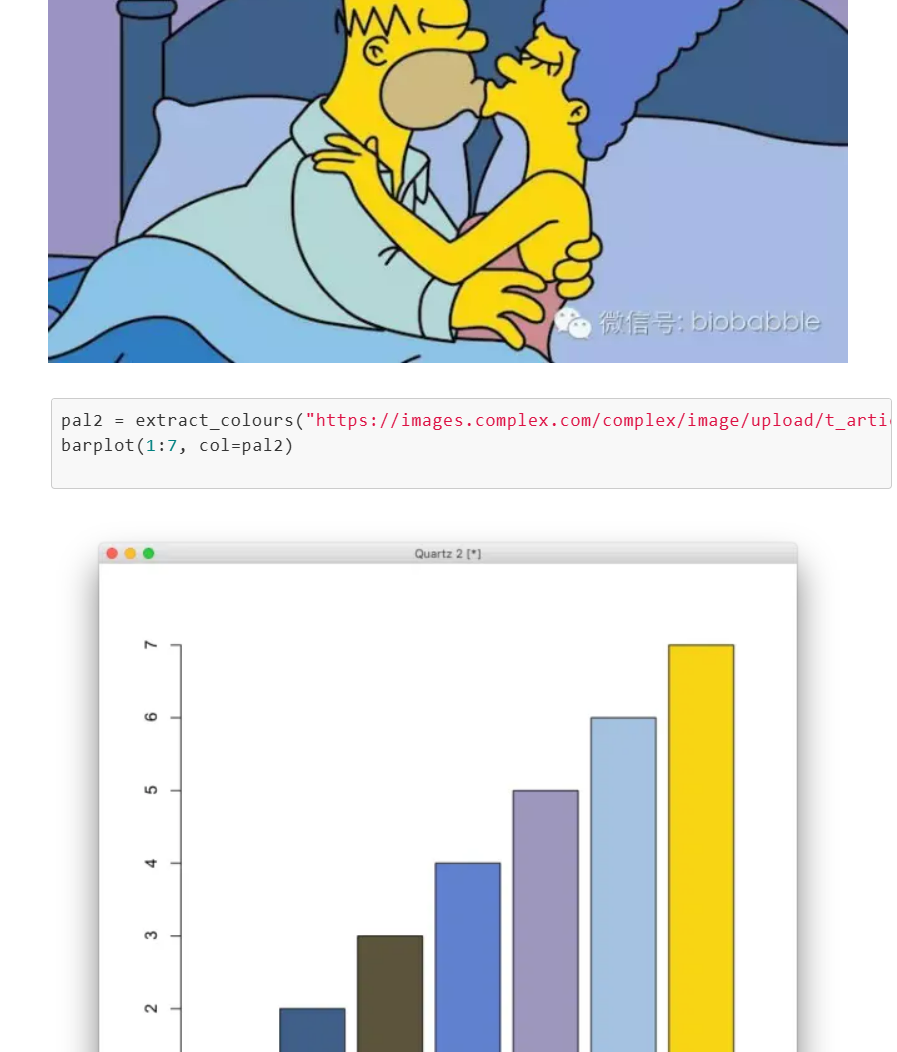
KMeans不能干啥
从前面说到的KMeans的两个假设,就可以看出来,不符合这两个假设,它就不能干啊。因为KMeans只能确定线性聚类边界,所以当边界很复杂的时候,它是做不好的。比如我在《AI学起来,毕竟AI让地球运转》里放的这张用SVM分类的图,用KMeans就做不好。
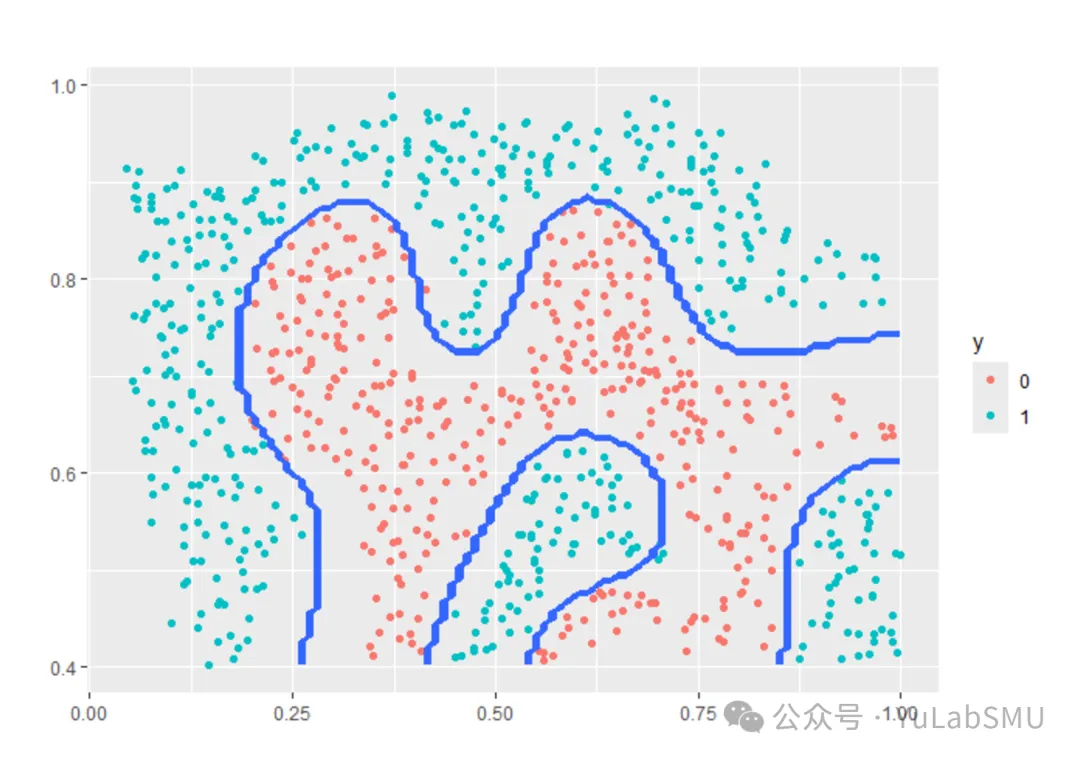
但是我们想一想,SVM是怎么做的?应用一个核函数,将数据投影到更高维的空间,然后是线性可分的,在高维空间进行分类。既然在高维空间是线性可分的,那么用KMeans也是可以的。所以像这种KMeans干不来的分类,如果我们组合一个核变换+KMeans,那么它也是干得来的。
欲知后事如何,请听下回分解。