没有GPU,无法AI :)
数据
这个数据是随机生成的,用的sklearn里的make_moons
RANDOM_SEED = 42
from sklearn.datasets import make_moons
n_samples = 1000
X, y = make_moons(n_samples = n_samples, noise = 0.2, random_state=RANDOM_SEED)画个图看一眼:
import pandas as pd
X_df = pd.DataFrame(X)
import matplotlib.pyplot as plt
plt.scatter(X_df[0], X_df[1], c=y)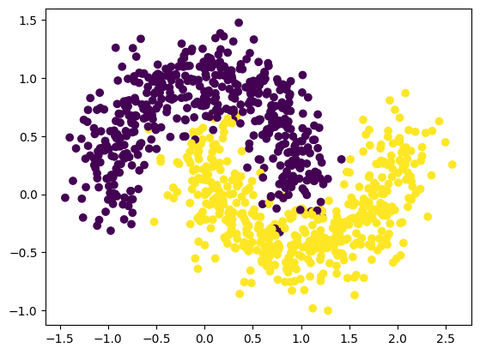
因为我们训练是在GPU上,所以数据我们需要也放到GPU上,再者数据要拆分为训练集和测试集,这里依然使用sklearn中的函数,train_test_split,80%的数据用于训练,20%的数据用于测试。
X = torch.tensor(X, dtype=torch.float).to(device)
y = torch.tensor(y, dtype=torch.float).to(device)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=RANDOM_SEED)模型
继续我们的PyTorch学习,上一次在《用PyTorch训练简单线性回归》中我们定义了继承nn.Module的类。对于简单的神经网络来说,我们用nn.Sequential就可以了,连forward函数都省了。
import torch
from torch import nn
BinaryClassification = nn.Sequential(
nn.Linear(in_features = 2, out_features = 10),
nn.ReLU(),
nn.Linear(in_features = 10, out_features = 10),
nn.ReLU(),
nn.Linear(in_features = 10, out_features = 1)
).to(device)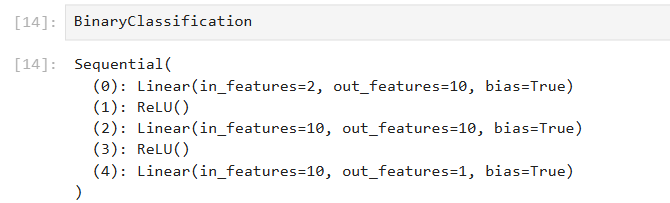
这里用的数据是个二维的数据,当然多少维都一样,就是in_features数改一下而已,这里二维,进来就接10个神经元,我们也可以认为是对数据进行了升维,然后再接10个神经元,最后的输出就是所谓的logit,所以分类叫logistic regression嘛。把这个logit值再过一个sigmoid函数,就是分类的概率了。这里每一层线性回归,都要加一个激活函数,这里用了ReLU,但也可以是别的。这就是我在《简单线性回归》最后写的:

损失函数
loss_fn = nn.BCEWithLogitsLoss()这里是分类,分类的损失函数可以用交叉熵(Cross Entropy),这里是二分类就有相应的Binary Cross Entropy,所谓损失函数,就是比较真实label和预测的label的差距,优化的过程就是希望这个差距越来越小。我们的模型输出的是logits,需要过一个sigmoid,才能预测label,然后才能使用交叉熵来计算损失,所以是两步。那么这里使用的nn.BCEWithLogitsLoss()就是整合了这两步,而且会比自己拆分两步来计算在数值上会更稳健一些。
优化器
optimizer = torch.optim.SGD(params = BinaryClassification.parameters(), lr = 0.1)这里用了torch.optim.SGD也就是随机梯度下降,这是很常见的优化器,这里设置学习率为0.1。
准确率
我们需要定义一个函数,来度量一下模型的准确率,这个函数很简单,就是预测的label和真实的label是否相等的平均值(相等的个数/总数)。虽然函数很简单,但我们不需要自己定义,可以用torchmetrics,用这个模块还能方便我们在需要的时候用更多的指标。
from torchmetrics.classification import Accuracy
acc_fn = Accuracy(task="multiclass", num_classes=2).to(device)训练模型
from timeit import default_timer as timer
start_time = timer()
epochs = 1000
for epoch in range(epochs):
## Training
BinaryClassification.train()
y_logits = BinaryClassification(X_train).squeeze()
y_pred = torch.round(torch.sigmoid(y_logits))
loss = loss_fn(y_logits, y_train)
acc = acc_fn(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
## Testing
BinaryClassification.eval()
with torch.inference_mode():
test_logits = BinaryClassification(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits))
test_loss = loss_fn(test_logits, y_test)
test_acc = acc_fn(test_pred, y_test)
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")
end_time = timer()这里使用了timeit来记录时间,epochs用了1000,其实不用这么多,很快就收敛了。每个epoch里分两段,一段是训练,就是数据进去,计算损失,优化参数。另一段是是用测试集进行测试,这里用了torch.inference_mode(),因为测试的时候,没有优化过程,也就不需要去跟踪参数,会更快更省内存,测试阶段就只需要把数据扔进模型,计算一个损失和准确率。
最后是每100个epochs,打印一下相应的信息,让我们了解模型训练的表现。

到了100个epochs的时候,准确率在训练集和测试集上都已经>80%了

所用的时间,不到3秒。
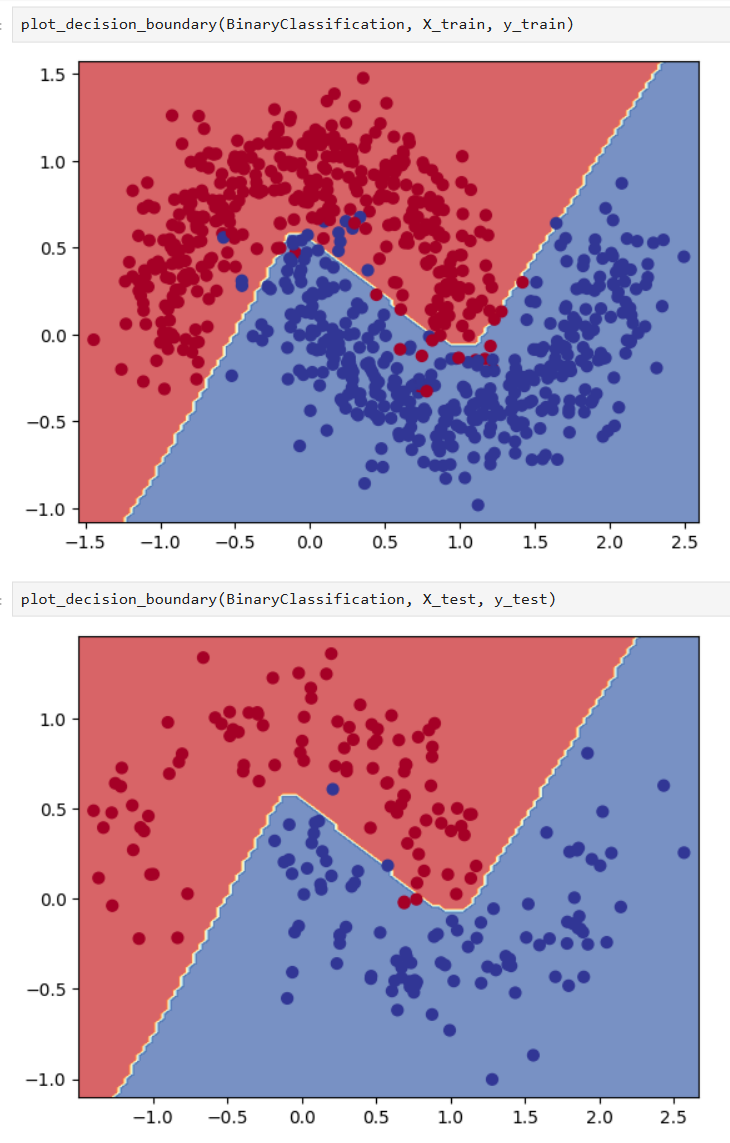
可视化
最后我们可以画一下,模型在训练集和测试集中的分类情况: