上一次说AI学起来,这就学起来。
先来个简单的线性回归。
假如要开一家餐馆,街区人口和利润是关联,从已经开的店的数据,预测一下,预测在新的街区开店的收入是多少。
读入数据
import pandas as pd
df = pd.read_csv("data/street-profits.csv", names=['population', 'profit'])df.head()
population profit
0 6.1101 17.5920
1 5.5277 9.1302
2 8.5186 13.6620
3 7.0032 11.8540
4 5.8598 6.8233线性回归
y = theta_0 + theta_1 * x,把 x加一个column是1,这样子就可以变成y = theta @ X.
import numpy as np
df['b'] = np.ones(df.shape[0])
X = df[['population', 'b']]
theta = np.zeros(X.shape[1])
y = df.profit用均方误差(MSE)来定义cost function。
def mse(theta, X, y):
# MSE: Mean Squared Error
m = X.size
inner = X @ theta - y
square_sum = inner.T @ inner
cost = square_sum / (2*m)
return cost线性回归变成一个优化的问题,就是让代价函数最小。进行偏微分,就可以得到参数更新的方向和大小。alpha是所谓的learning rate。
:= \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} \bigl( h_\theta(x^{(i)}) - y^{(i)} \bigr) x_j^{(i)}$$ 这个公式其实是我们大一都学过的泰勒公式。  在x接近a的时候,(x-a)就很少,后面多次方的项就可以忽略,这就成为了上面的公式了,而这个(x-a)就是alpha,就是在这里被称为learning rate的这一项,也就是说这个公式本身要成立,前提就是alpha很小。 下面的`gradient`函数算的就是偏微分的这块: ```python def gradient(theta, X, y): m = X.size inner = X.T @ (X @ theta - y) return inner/m ``` ### 批量梯度下降算法 按照上面的公式来计算。 ```python def batch_gradient_descent(theta, X, y, epoch, alpha=0.01): cost_data = [mse(theta, X, y)] _theta = theta.copy() for _ in range(epoch): _theta = _theta - alpha * gradient(_theta, X, y) cost_data.append(mse(_theta, X, y)) return _theta, cost_data ``` 搞个5000次迭代,出来最后的参数: ```python epoch = 5000 final_theta, cost_data = batch_gradient_descent(theta, X, y, epoch) ``` ## scikit-learn 比较一下,才知道行不行。 ```python from sklearn import linear_model model = linear_model.LinearRegression() model.fit(X, y)` ``` 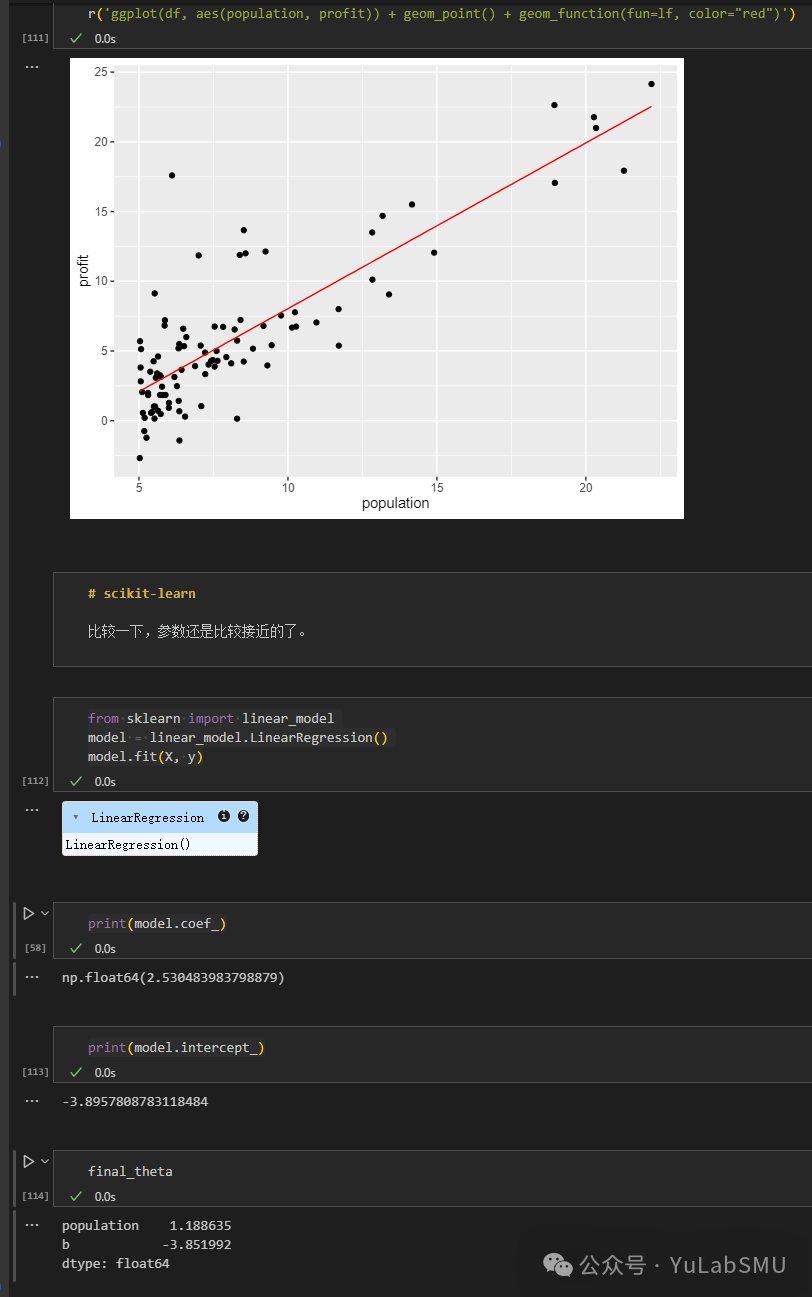 学会了线性回归,就离神经网络不远了😄 因为每个神经元都是一个线性回归,再加一个激活函数。神经网络就是一堆神经元,而再多的线性回归组合在一起,它还是一个线性函数,以二维来说,就还是一条直线,那有没有办法拟合任意曲线,那就需要带拐弯的,这就是激活函数要干的事,简单如ReLU,就是带个拐,就可以了。有拐弯,只要够多,经过缩放、位移、组合,就可以各种拐,而只要点足够多,直线拐也能平滑地拟和曲线,所以它就能拟合所有曲线,推广到高维空间,也是一样。