书接上一回,对于线性不可分的数据,怎么用KMeans来做聚类。
数据
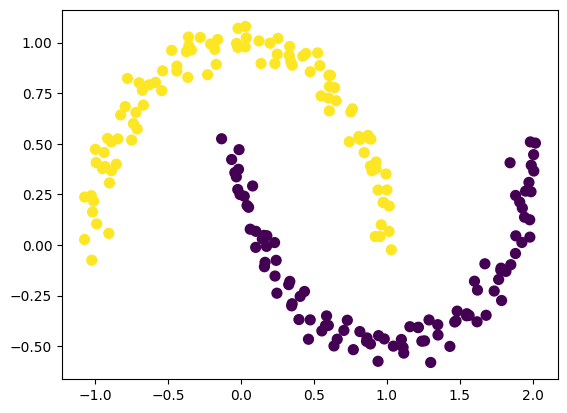
用make_moons来生成一个比较复杂的流形数据。
from sklearn.datasets import make_moons
X, y = make_moons(200, noise=0.05, random_state=0)画图看一下,数据是长这样子的:
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], s=50, c=y, cmap='viridis')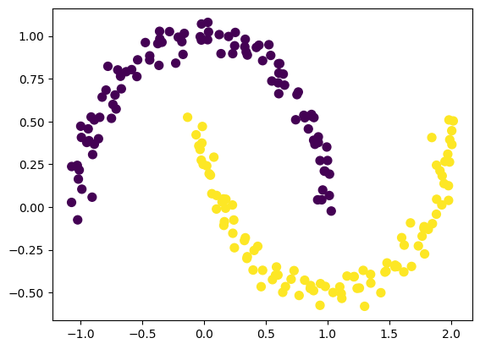
简单的KMeans是分不好的
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2)
labels = kmeans.fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')我们用KMeans来聚类,然后用聚类结果进行上色:
效果只能说不行。
t-SNE + KMeans
做过单细胞分析的,都知道t-SNE,当然你也可以试试UMAP,效果应该差不多。t-SNE擅长捕捉局部结构,就特别适合这种流形数据。它在高维空间用高斯分布计算样本间的相似度,然后用t分布匹配高维概率分布,通过梯度下降优化低维嵌入,优化目标是最小化高维和低维概率分布的KL散度。
我们对数据先进行标准化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)再进行t-SNE的变换:
from sklearn.manifold import TSNE
X_tsne = TSNE(n_components=2, perplexity=30, random_state=42).fit_transform(X_scaled)
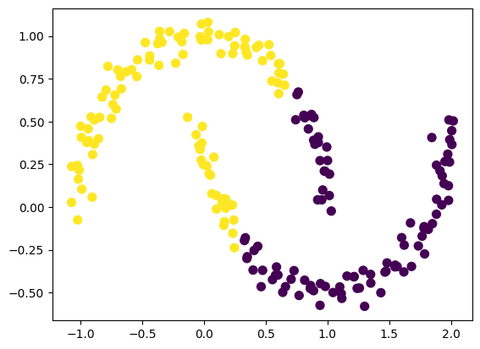
y_tsne_kmeans = KMeans(n_clusters=2).fit_predict(X_tsne)这时候,我们可以对变换后的数据进行可视化:
plt.scatter(X_tsne[:,0], X_tsne[:,1], c=y, cmap='viridis', s=50)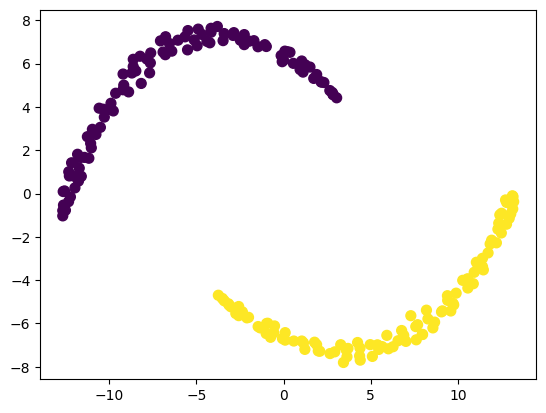
非常好地保留了原来的分类信息,然后这个数据就成了线性可分了。
那么我们可以可视化原始的数据,并用KMeans聚类结果进行上色,看看聚类效果如何:
plt.scatter(X[:, 0], X[:, 1], c=y_tsne_kmeans, s=50, cmap='viridis')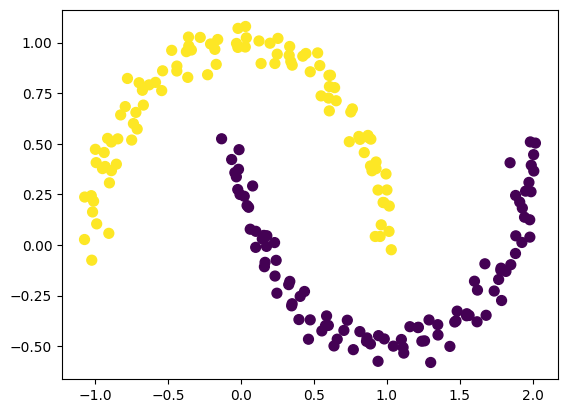
谱聚类
谱聚类本质上就是核KMeans的优化版本,就是上次说的应用核函数再加KMeans,当然如果你自己这么简单做了,效果可能不太好,因为谱聚类做得更多,所以更加鲁棒。它先计算一个相似度矩阵(可以通过高斯核函数+欧式距离,也可以通过KNN连接矩阵),再构建拉普拉斯矩阵对相似度矩阵进行归一化,再计算特征向量(本质就是低维嵌入),然后对特征向量运行KMeans。
from sklearn.cluster import KMeans, SpectralClustering
spectral = SpectralClustering(n_clusters=2,
affinity='rbf',
gamma=15,
random_state=42)
y_spectral = spectral.fit_predict(X_scaled)
plt.scatter(X[:, 0], X[:, 1], c=y_spectral, s=50, cmap='viridis')这里我就用了affinity='rbf'也就是高斯核函数,gamma这个参数控制高斯核函数的宽度,数据复杂的情况下,gamma就可以调大一点试试。最后的聚类结果效果就非常好。