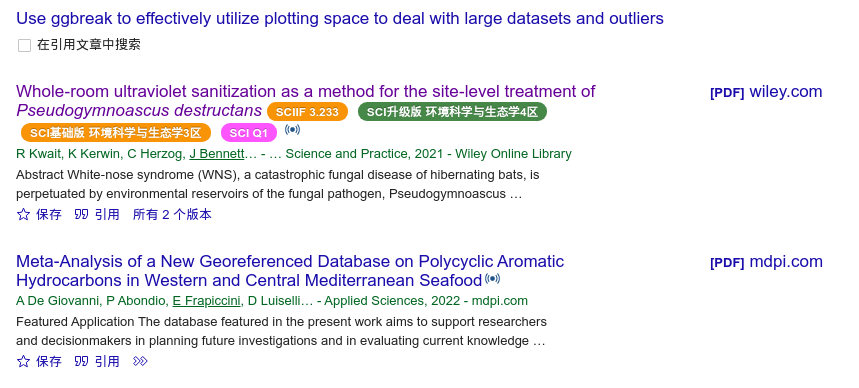
下图是我们文章中的例子,当一个序列型(比如说时间序列)的数据很长的时候,是不容易看到细节的,最主要是打印在A4纸上,空间有限,把它像B图一样,分成几行,就好了,把往右边要空间的需求,变成了往下边要空间。右边空间要不来,但下面有的是。
另一方面,比如说时间序列吧,比如是是新冠疫情的数据吧,分成几行还有一个好处,可以比较不同周期的同一时间点的数据。
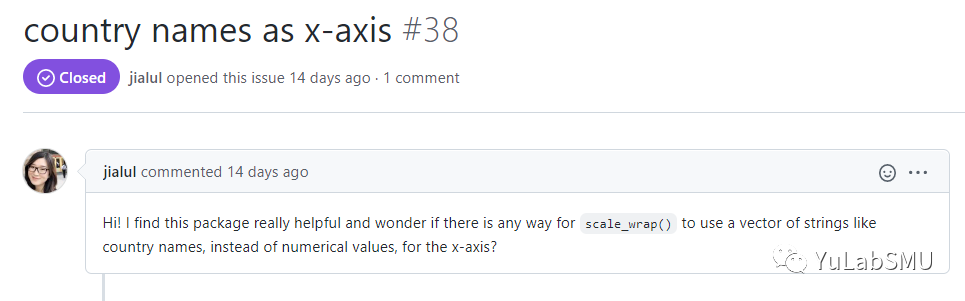
这个功能在我们ggbreak包中的scale_wrap()函数实现,但原来只支持数值型的数据。
用户问x轴能不能用国家名称,更通用地说,也就是能不能是分类型变量?
又有用户说,TA画小提琴图,报错,其实也是因为不支持分类型变量的缘故。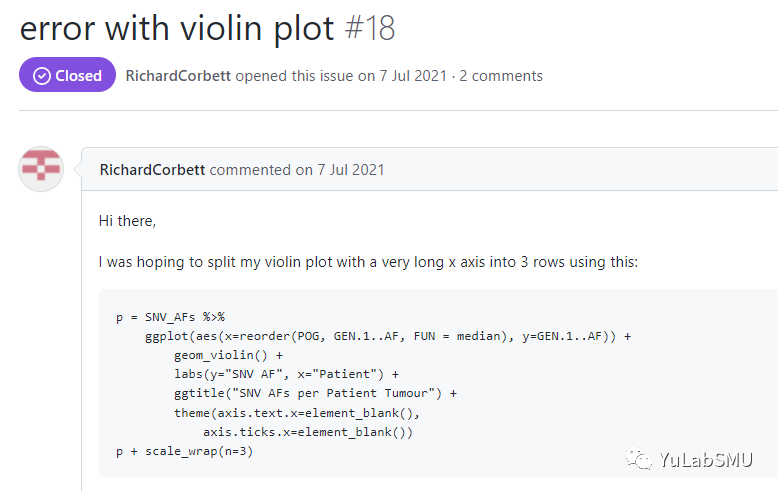
婶能忍,叔不能忍。于是我们搞搞又支持了。这个功能在0.0.9及以上版本中,当前已经可以通过CRAN拥有它。来人上栗子:
library(ggplot2)
library(ggbreak)
p <- ggplot(mpg, aes(class, hwy))
p <- p + geom_violin()
小提琴图如下:
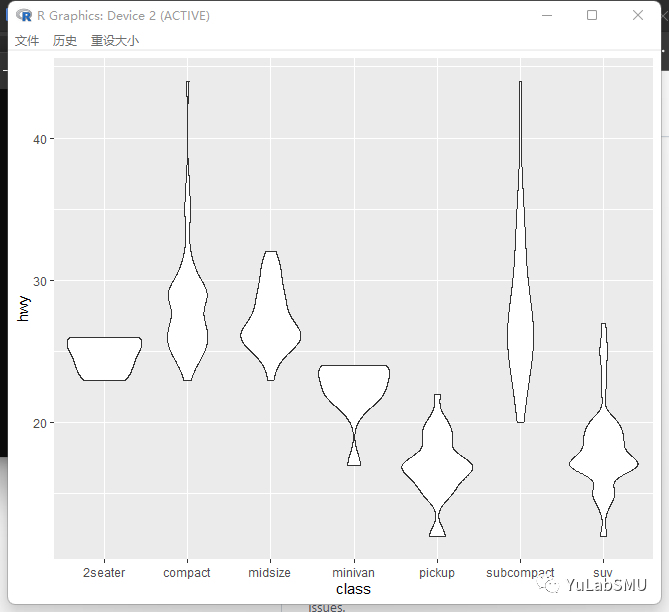
p1 <- p + scale_wrap(2)
搞成两行,出图如下:
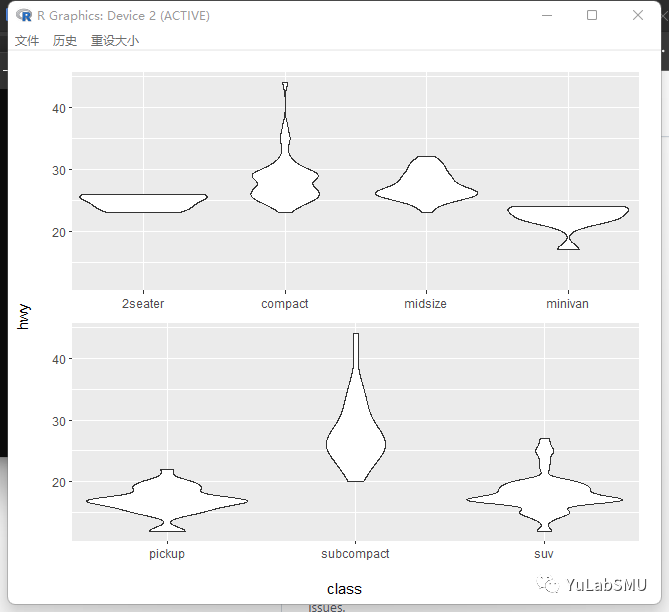
简直完美。
让我们再来玩点别的,我想既然是分类型变量,你们肯定会想搞一个事情,那就是自己定义位置,这个当然很容易,通过因子来设定嘛,我们能兼容么?当然可以!
假设我们要使用以下的顺序来画图:
> set.seed(123)
> lv = sample(unique(mpg$class), 7)
> lv
[1] "subcompact" "suv" "pickup" "midsize" "2seater"
[6] "minivan" "compact"
这个容易得很,随便搞,反正怎么搞都行,都是兼容的。
> p1 + aes(x=factor(class, levels=lv))
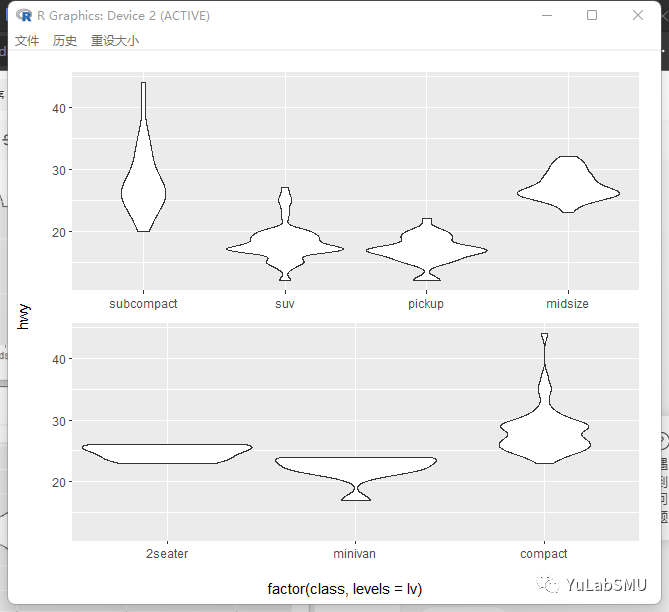
ggbreak开始有引用了呀: